Chapter 3 Use case 1: basic use of joint_model()
This first use case will show how to fit and interpret the joint model with paired eDNA and traditional survey data.
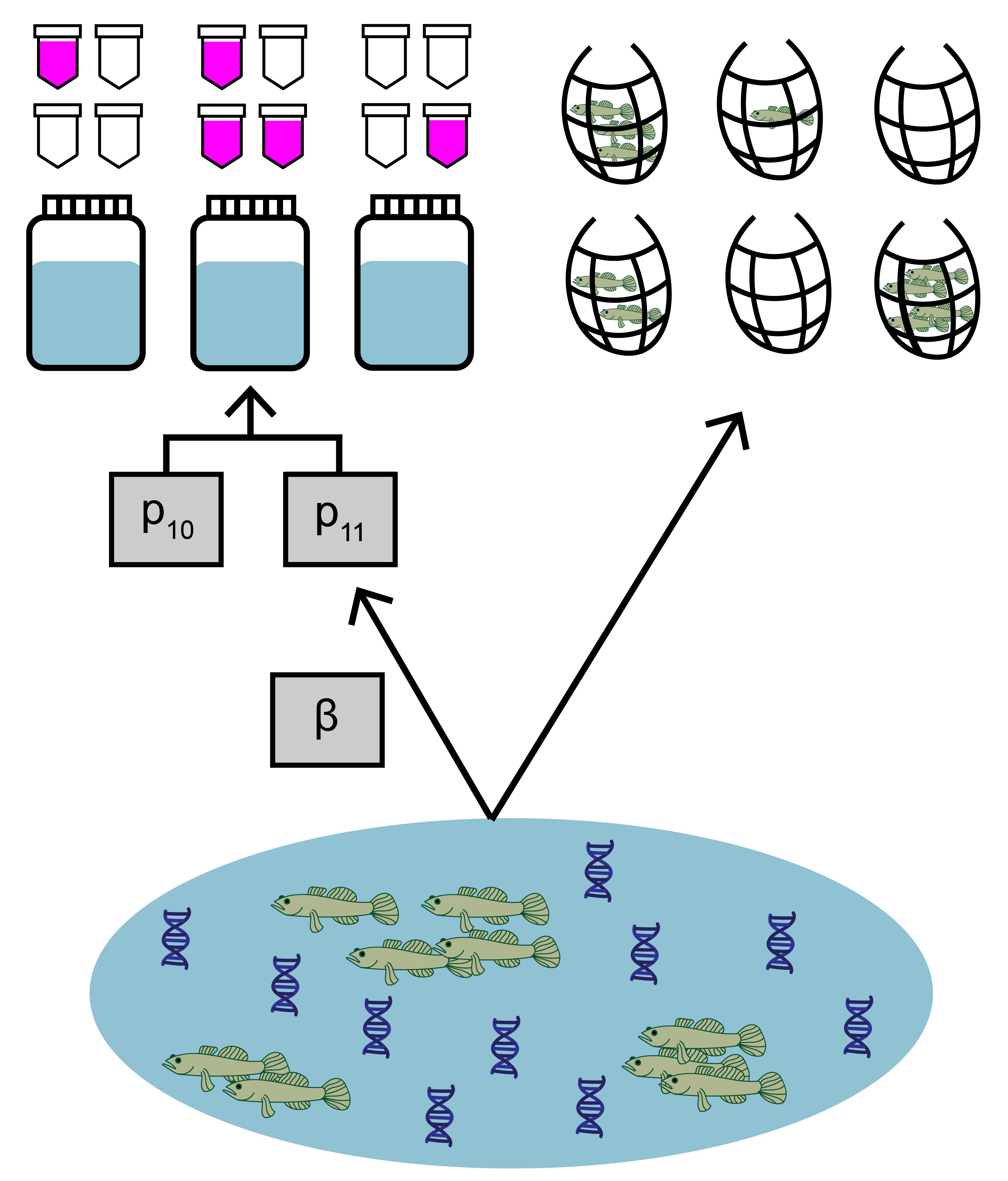
The data used in this example comes from a study by Schmelzle and Kinziger (2016) about endangered tidewater gobies (Eucyclogobius newberryi) in California. Environmental DNA samples were collected at 39 sites, along with paired traditional seine sampling. The eDNA data is detection/non-detection data generated through quantitative polymerase chain reaction (qPCR).
3.1 Prepare the data
Both eDNA and traditional survey data should have a hierarchical structure:
- Sites (primary sample units) within a study area
- eDNA and traditional samples (secondary sample units) collected from each site
- eDNA subsamples (replicate observations) taken from each eDNA sample
Ensuring that your data is formatted correctly is essential for successfully using eDNAjoint. Let’s first explore the structure of the goby data.
## List of 4
## $ pcr_n : num [1:39, 1:22] 6 6 6 6 6 6 6 6 6 6 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : NULL
## .. ..$ : chr [1:22] "1" "2" "3" "4" ...
## $ pcr_k : num [1:39, 1:22] 0 0 0 0 6 0 0 0 0 5 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : NULL
## .. ..$ : chr [1:22] "1" "2" "3" "4" ...
## $ count : int [1:39, 1:22] 0 0 0 0 0 0 0 0 0 1 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : NULL
## .. ..$ : chr [1:22] "1" "2" "3" "4" ...
## $ site_cov: num [1:39, 1:5] -0.711 -0.211 -1.16 -0.556 -0.988 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : NULL
## .. ..$ : chr [1:5] "Salinity" "Filter_time" "Other_fishes" "Hab_size" ...You can see that the data is a list of four matrices all with the same number of rows that represent each site (n=39). Across all matrices, rows in the data should correspond to the same sites (i.e., row one in all matrices corresponds to site one, and row 31 in all matrices corresponds to site 31).
pcr_k, pcr_n, and count are required for all implementations of joint_model(), and site_cov is optional and will be used in use case 2.
Let’s look first at pcr_k. These are the total number of positive PCR detections for each site (row) and eDNA sample (column). The number of columns should equal the maximum number of eDNA samples collected at any site. Blank spaces are filled with NA at sites where fewer eDNA samples were collected than the maximum.
For example, at site one, 11 eDNA samples were collected, and at site five, 20 eDNA samples were collected.
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
## [1,] 0 0 0 0 0 0 0 0 0 0 0 NA NA NA NA NA NA NA NA NA NA NA
## [2,] 0 0 0 0 0 0 0 0 0 0 0 NA NA NA NA NA NA NA NA NA NA NA
## [3,] 0 0 0 0 0 0 0 0 0 0 0 NA NA NA NA NA NA NA NA NA NA NA
## [4,] 0 6 6 4 6 5 4 6 5 3 NA NA NA NA NA NA NA NA NA NA NA NA
## [5,] 6 6 4 6 6 6 5 4 2 2 0 6 5 5 6 6 6 5 5 4 NA NA
## [6,] 0 0 0 NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NANow let’s look at pcr_n. These are the total number of PCR eDNA subsamples (replicate observations) collected for each site (row) and eDNA sample (column). In this data, six PCR replicate observations were collected for each eDNA sample. Notice that the locations of the NAs in the matrix match pcr_k.
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
## [1,] 6 6 6 6 6 6 6 6 6 6 6 NA NA NA NA NA NA NA NA NA NA NA
## [2,] 6 6 6 6 6 6 6 6 6 6 6 NA NA NA NA NA NA NA NA NA NA NA
## [3,] 6 6 6 6 6 6 6 6 6 6 6 NA NA NA NA NA NA NA NA NA NA NA
## [4,] 6 6 6 6 6 6 6 6 6 6 NA NA NA NA NA NA NA NA NA NA NA NA
## [5,] 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 NA NA
## [6,] 6 6 6 NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NANext, let’s look at count. This data is from seine sampling for tidewater gobies. Each integer refers to the catch of each seine sample (i.e., catch per unit effort, when effort = 1). Again, the rows correspond to sites, and the columns refer to replicated seine samples (secondary sample units) at each site, with a maximum of 22 samples. Blank spaces are filled with NA at sites where fewer seine samples were collected than the maximum.
In this example, the count data are integers, but continuous values can be used in the model (see Eq. 1.3 in the model description).
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
## [1,] 0 0 0 0 0 0 0 0 0 0 0 NA NA NA NA NA NA NA NA NA NA NA
## [2,] 0 0 0 0 0 0 0 0 0 0 0 NA NA NA NA NA NA NA NA NA NA NA
## [3,] 0 0 0 0 0 0 0 0 0 0 0 NA NA NA NA NA NA NA NA NA NA NA
## [4,] 0 4 1 0 2 1 38 112 1 15 NA NA NA NA NA NA NA NA NA NA NA NA
## [5,] 0 0 0 2 0 0 0 0 0 0 0 0 4 1 0 2 0 8 NA NA NA NA
## [6,] 0 0 0 NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA3.1.1 Converting data from long to wide
Using eDNAjoint requires your data to be in “wide” format. Wide vs. long data refers to the shape of your data in tidyverse jargon (see more here). Below is an example for how to convert your data to wide format.
First let’s simulate “long” PCR data.
## data dimensions
# number of sites (primary sample units)
nsite <- 4
# number of eDNA samples (secondary sample units)
n_edna_samples <- 6
# number of traditional samples (secondary sample units)
n_traditional_subsamples <- 8
# number of eDNA subsamples (replicate observations)
n_edna_subsamples <- 3
# simulate PCR data
pcr_long <- data.frame(
site = rep(1:nsite, each = n_edna_samples),
eDNA_sample = rep(1:n_edna_samples, times = nsite),
N = rep(n_edna_subsamples, nsite * n_edna_samples),
K = c(
rbinom(n_edna_samples, n_edna_subsamples, 0.1), # site 1 positive detections
rbinom(n_edna_samples, n_edna_subsamples, 0.6), # site 2 positive detections
rbinom(n_edna_samples, n_edna_subsamples, 0), # site 3 positive detections
rbinom(n_edna_samples, n_edna_subsamples, 0.4) # site 4 positive detections
)
)
head(pcr_long)## site eDNA_sample N K
## 1 1 1 3 0
## 2 1 2 3 0
## 3 1 3 3 0
## 4 1 4 3 0
## 5 1 5 3 2
## 6 1 6 3 0And simulate “long” traditional data:
# simulate traditional count data
count_long <- data.frame(
site = rep(1:nsite, each = n_traditional_subsamples),
traditional_sample = rep(1:n_traditional_subsamples, times = nsite),
count = c(
rpois(n_traditional_subsamples, 0.5), # site 1 count data
rpois(n_traditional_subsamples, 4), # site 2 count data
rpois(n_traditional_subsamples, 0), # site 3 count data
rpois(n_traditional_subsamples, 2) # site 4 count data
)
)
head(count_long)## site traditional_sample count
## 1 1 1 0
## 2 1 2 0
## 3 1 3 0
## 4 1 4 0
## 5 1 5 0
## 6 1 6 0Now let’s convert the data from “long” to “wide”.
# N: number of PCR eDNA subsamples (i.e., replicate observations)
# per eDNA sample (i.e., secondary sample)
pcr_n_wide <- pcr_long %>%
pivot_wider(id_cols = site,
names_from = eDNA_sample,
values_from = N) %>%
arrange(site) %>%
select(-site)
# K: number of positive PCR detections in each
# eDNA sample (i.e., secondary sample)
pcr_k_wide <- pcr_long %>%
pivot_wider(id_cols = site,
names_from = eDNA_sample,
values_from = K) %>%
arrange(site) %>%
select(-site)
# count: number of individuals in each traditional sample
# (i.e., secondary sample)
count_wide <- count_long %>%
pivot_wider(id_cols = site,
names_from = traditional_sample,
values_from = count) %>%
arrange(site) %>%
select(-site)Finally, we’ll bundle this data up into a named list of matrices.
3.2 Fit the model
Now that we understand our data, let’s fit the joint model. The key arguments of this function include:
- data: list of
pcr_k,pcr_n, andcountmatrices - family: probability distribution used to model the seine count data. A poisson distribution is chosen here.
- p10_priors: Beta distribution parameters for the prior on the probability of false positive eDNA detection, \(p_{10}\). c(1, 20) is the default specification. More on this later.
- q: logical value indicating the presence of multiple traditional gear types. Here, we’re only using data from one traditional method.
More parameters exist to further customize the MCMC sampling, but we’ll stick with the defaults.
# run the joint model
goby_fit1 <- joint_model(data = goby_data, family = "poisson",
p10_priors = c(1, 20), q = FALSE,
multicore = TRUE)goby_fit1 is a list containing:
- model fit (
goby_fit1$model) of the class ‘stanfit’ and can be accessed and interpreted using all functions in the rstan package. - initial values used for each chain in MCMC (
goby_fit1$inits)
3.3 Interpret the output
3.3.1 Summarize posterior distributions
Let’s interpret goby_fit1. Use joint_summarize() to see the posterior summaries of the model parameters.
## mean se_mean sd 2.5% 97.5% n_eff Rhat
## p10 0.002 0.000 0.001 0.001 0.003 14738.28 1
## alpha[1] 0.657 0.001 0.094 0.470 0.841 10075.73 1This summarizes the mean, standard deviation (sd), and quantiles of the posterior estimates of \(p_{10}\) and \(\alpha\), as well as the effective sample size (n_eff) and \(\hat{R}\) (Rhat) for the parameters. More informative about effective sample size and \(\hat{R}\) can be found in the algorithm convergence section, but briefly, the \(\hat{R}\) value is the frequently used statistic for assessing model convergence. We typically want \(\hat{R}\) to be less than 1.05, so it looks like our model converged.
The mean estimated probability of a false positive eDNA detection is 0.001, and the 2.5% and 97.5% quantiles show the bounds of the 95% credibility interval (the equal tailed credibility interval, to be specific.)
\(\alpha\) are regression coefficients that scale the sensitivity of eDNA relative to traditional sampling. Since there were no site-level covariates in this model, \(\alpha\) is just a scalar, intercept term (see Eq. 4 in model description).
The parameter \(\beta_i\) represents the site-specific sensitivity of eDNA relative to traditional sampling. We use \(i\) to index the sites. Since we don’t have any site-level covariates here, \(\beta\) is equal at all sites and equal to \(\alpha_1\). For example, here are the first few \(\beta_i\):
## mean se_mean sd 2.5% 97.5% n_eff Rhat
## alpha[1] 0.657 0.001 0.094 0.47 0.841 10075.73 1
## beta[1] 0.657 0.001 0.094 0.47 0.841 10075.73 1
## beta[2] 0.657 0.001 0.094 0.47 0.841 10075.73 1
## beta[3] 0.657 0.001 0.094 0.47 0.841 10075.73 1
## beta[4] 0.657 0.001 0.094 0.47 0.841 10075.73 1
## beta[5] 0.657 0.001 0.094 0.47 0.841 10075.73 1\(\beta\) exists on the real line (i.e., ranges from negative infinity to infinity). See Equation 3 in the model description for how it’s included. Since \(\beta\) is in the denominator of this equation, as \(\beta\) increases, eDNA becomes less sensitive, relative to traditional sampling.
An example of exploring this in R:
## [1] 0.45186276 0.15536240 0.06337894Here, given an expected catch rate (\(\mu\)) of 0.5 and these values of \(\beta\), \(p_{11}\) (probability of true positive eDNA detection) would be: 0.45, 0.16, 0.063. Here you see that the lowest value of \(\beta\) (-0.5) corresponds to the highest value of \(p_{11}\) (0.45), and the highest value of \(\beta\) (2) corresponds to the lowest value of \(p_{11}\) (0.063).
We can also use functions from the bayesplot package to examine the posterior distributions and chain convergence.
First let’s look at the posterior distribution for \(p_{10}\).
library(bayesplot)
# plot posterior distribution, highlighting median and 80% credibility interval
mcmc_areas(as.matrix(goby_fit1$model), pars = "p10", prob = 0.8)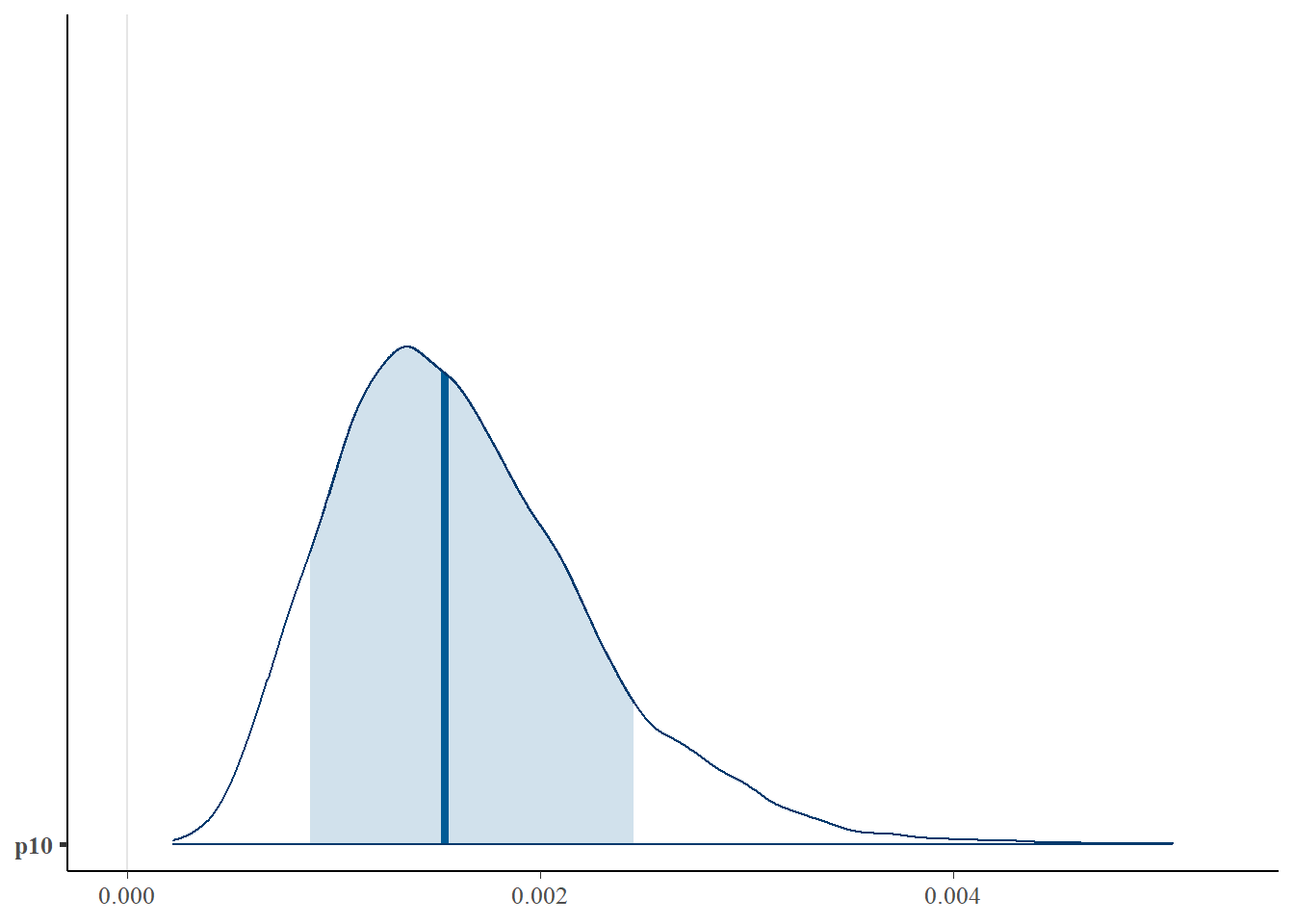
Next let’s look at chain convergence for \(p_{10}\) and \(\mu_{i=1,k=1}\).
# this will plot the MCMC chains for p10 and mu at site 1
mcmc_trace(rstan::extract(goby_fit1$model, permuted = FALSE),
pars = c("p10", "mu[1,1]"))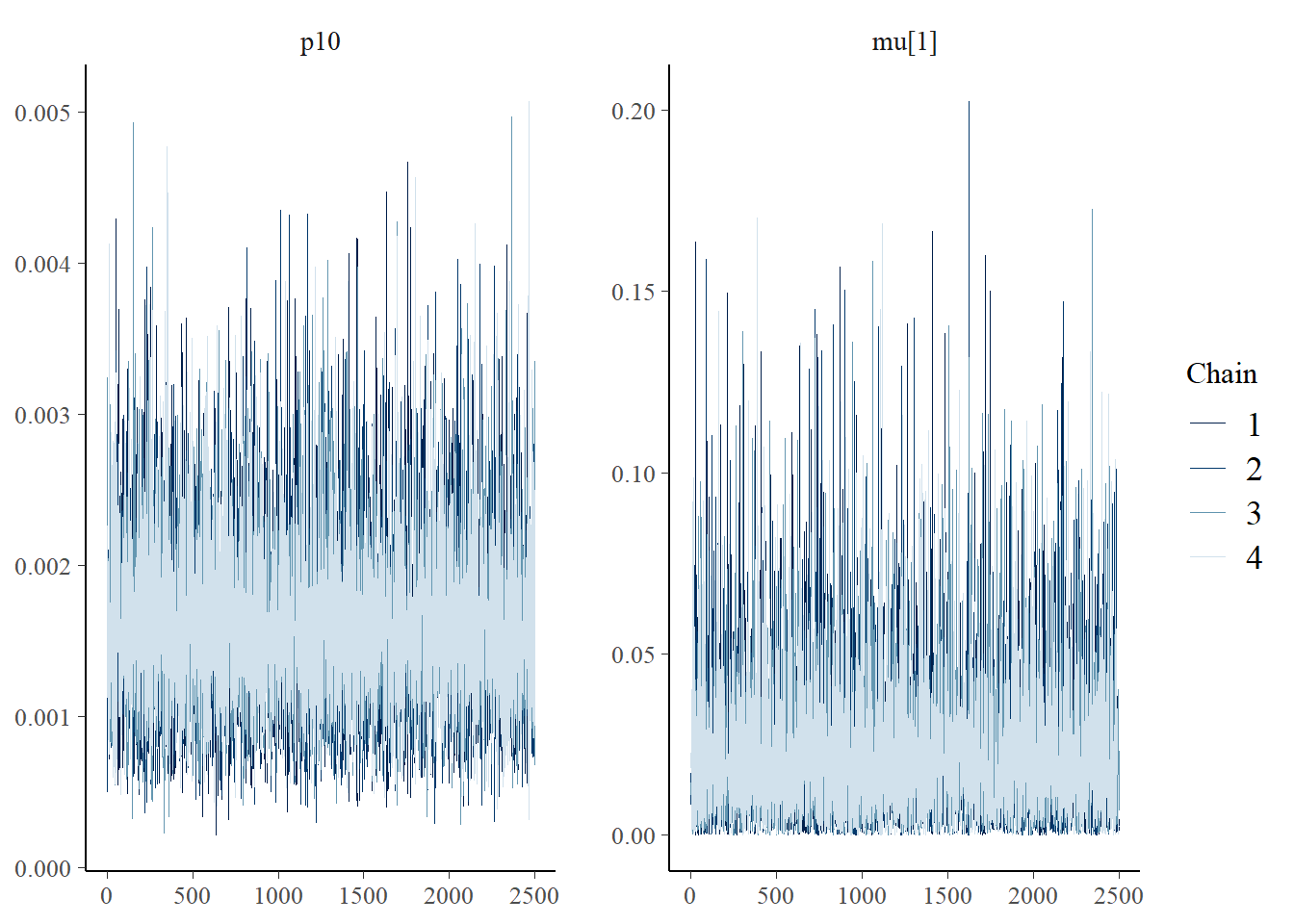
These trace plots show that the algorithm has converged. The chains are overlapping and stationary (i.e., are moving around the same mean and have a constant variance). See more about trace plots in the algorithm convergence section.
3.3.2 Effort necessary to detect presence
To further highlight the relative sensitivity of eDNA and traditional sampling, we can use detection_calculate() to find the units of survey effort necessary to detect presence of the species. Here, detecting presence refers to producing at least one true positive eDNA detection or catching at least one individual in a traditional survey.
This function is finding the median number of survey units necessary to detect species presence if the expected catch rate, \(\mu\) is 0.1, 0.5, or 1.
## mu n_traditional n_eDNA
## [1,] 0.1 24 16
## [2,] 0.5 5 4
## [3,] 1.0 3 2We can also plot these comparisons. mu_min and mu_max define the x-axis in the plot.
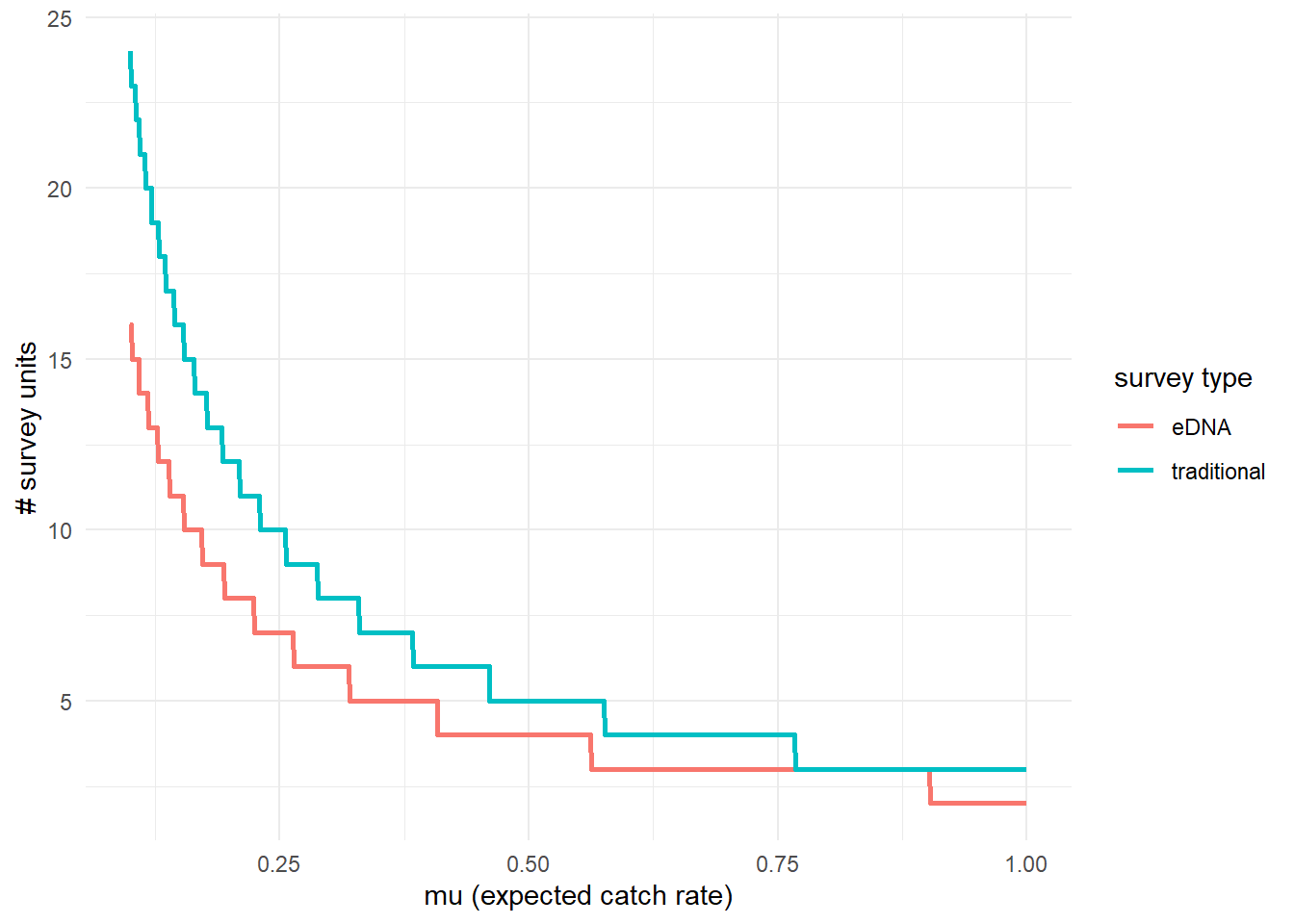
3.3.3 Calculate \(\mu_{critical}\)
The probability of a true positive eDNA detection, \(p_{11}\), is a function of the expected catch rate, \(\mu\). Low values of \(\mu\) correspond to low probability of eDNA detection. Since the probability of a false-positive eDNA detection is non-zero, the probability of a false positive detection may be higher than the probability of a true positive detection at very low values of \(\mu\).
\(\mu_{critical}\) describes the value of \(\mu\) where the probability of a false positive eDNA detection equals the probability of a true positive eDNA detection. This value can be calculated using mu_critical().
## $median
## [1] 0.002948645
##
## $lower_ci
## Highest Density Interval: 1.18e-03
##
## $upper_ci
## Highest Density Interval: 5.12e-03This function calculates \(\mu_{critical}\) using the entire posterior distributions of parameters from the model, and ‘HDI’ corresponds to the 90% credibility interval calculated using the highest density interval.
3.4 Prior sensitivity analysis
The previous model implementation used default values for the beta prior distribution for \(p_{10}\). The choice of these prior parameters can impose undue influence on the model’s inference. The best way to investigate this is to perform a prior sensitivity analysis.
Let’s look at how three prior choices affect the posterior estimates of \(p_{10}\) and \(\alpha\).
Prior choice 1: default prior parameters c(1, 20). The mean and sd of this prior distribution are 0.048 and 0.045, respectively.
## mean se_mean sd 2.5% 97.5% n_eff Rhat
## p10 0.002 0.000 0.001 0.001 0.003 14738.28 1
## alpha[1] 0.657 0.001 0.094 0.470 0.841 10075.73 1Prior choice 2: c(1, 15). The mean and sd of this prior distribution are 0.063 and 0.058, respectively.
fit_prior2 <- joint_model(data = goby_data, family = "poisson",
p10_priors = c(1, 15), q = FALSE,
multicore = TRUE)## mean se_mean sd 2.5% 97.5% n_eff Rhat
## p10 0.002 0.000 0.001 0.001 0.003 16278.22 1
## alpha[1] 0.660 0.001 0.095 0.473 0.846 10078.46 1Prior choice 3: c(1, 10). The mean and sd of this prior distribution are 0.091 and 0.083, respectively.
fit_prior3 <- joint_model(data = goby_data, family = "poisson",
p10_priors = c(1, 10), q = FALSE,
multicore = TRUE)## mean se_mean sd 2.5% 97.5% n_eff Rhat
## p10 0.002 0.000 0.001 0.001 0.004 20013.56 1
## alpha[1] 0.666 0.001 0.094 0.483 0.849 11906.05 1We can also plot our prior distributions and posterior distributions for \(p_{10}\) to further explore this sensitivity.
library(wesanderson)
library(patchwork)
# get samples
samples_20 <- rstan::extract(fit_prior1, pars = "p10")$p10
samples_10 <- rstan::extract(fit_prior2$model, pars = "p10")$p10
samples_30 <- rstan::extract(fit_prior3$model, pars = "p10")$p10
# plot
prior_plot <- ggplot() +
geom_density(aes(x = rbeta(100000, 1, 20)), color = wes_palette("Zissou1")[1],
linetype = "dashed") + # blue
geom_density(aes(x = rbeta(100000, 1, 10)), color = wes_palette("Zissou1")[3],
linetype = "dashed") + # yellow
geom_density(aes(x = rbeta(100000, 1, 30)), color = wes_palette("Zissou1")[5],
linetype = "dashed") + # red
scale_x_continuous(limits = c(0, 0.15)) +
labs(x = "p10 value", y = "density") +
ggtitle("A. p10 prior distribution") +
theme_minimal()
posterior_plot <- ggplot() +
geom_density(aes(x = samples_20), color = wes_palette("Zissou1")[1]) +
geom_density(aes(x = samples_10), color = wes_palette("Zissou1")[3]) +
geom_density(aes(x = samples_30), color = wes_palette("Zissou1")[5]) +
scale_x_continuous(limits = c(0, 0.15)) +
labs(x = "p10 value", y = "density") +
ggtitle("B. p10 posterior distribution") +
theme_minimal()
prior_plot + posterior_plot + plot_layout(ncol = 1)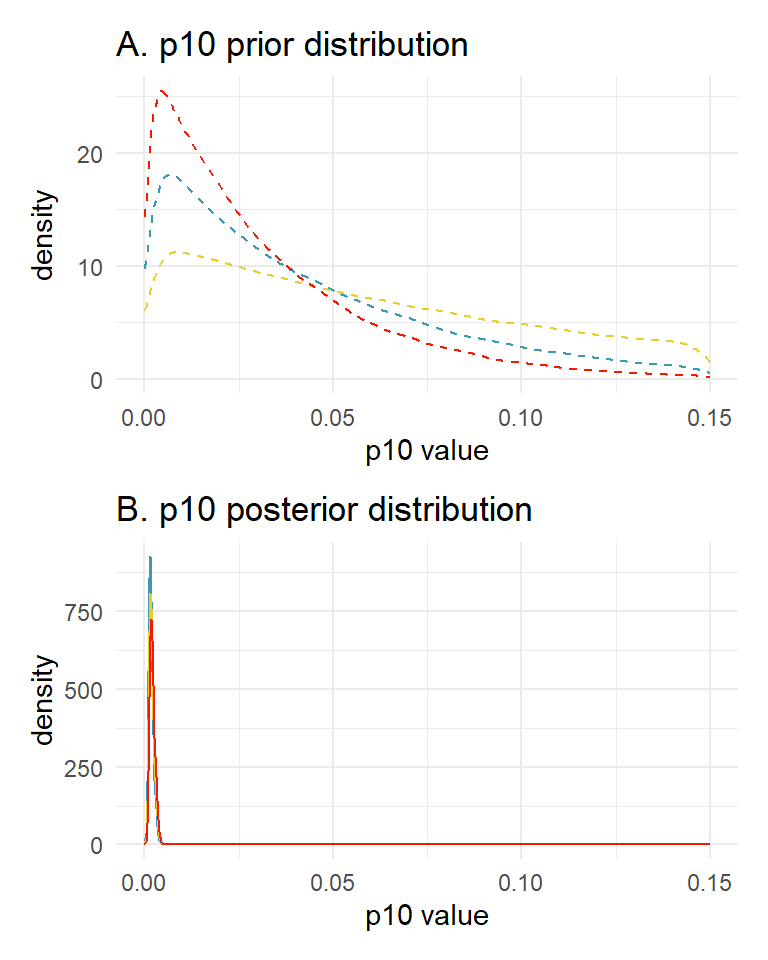
You can see that the choice of the \(p_{10}\) prior within this range has little influence on the estimated parameters.
3.5 Initial values
By default, eDNAjoint will provide initial values for parameters estimated by the model, but you can provide your own initial values if you prefer. Here is an example of providing initial values for parameters, mu,p10, and alpha, as an input in joint_model().
# set number of chains
n_chain <- 4
# number of sites
nsites <- dim(goby_data$count)[1]
# initial values should be a list of named lists
inits <- list()
for (i in 1:n_chain) {
inits[[i]] <- list(
# length should equal the number of sites
mu = stats::runif(nsites, 0.01, 5),
# length should equal 1 for each chain
p10 = stats::runif(1, 0.0001, 0.08),
# length should equal 1 for each chain,
# since there are no site-level covariates
alpha = stats::runif(1, 0.05, 0.2)
)
}# now fit the model
fit_inits <- joint_model(data = goby_data, initial_values = inits,
multicore = TRUE)## $chain1
## $chain1$mu_trad
## [1] 4.91511171 4.37824405 4.16167048 0.58223507 4.77754927 1.07076683 1.24342658
## [8] 3.35766657 4.45391302 1.38907859 2.30148079 4.63637723 3.45937412 2.94930292
## [15] 1.44009535 1.24663143 0.54124695 3.65451204 1.50108508 2.23773351 0.63007357
## [22] 2.62351713 2.37921356 0.07420163 2.12444757 4.67965217 4.44459193 1.39030676
## [29] 4.99919658 1.83741560 1.42966575 1.64082222 0.80555428 2.14070414 2.63217911
## [36] 1.20162470 0.47279641 4.33864937 4.72580666
##
## $chain1$mu
## [1] 4.91511171 4.37824405 4.16167048 0.58223507 4.77754927 1.07076683 1.24342658
## [8] 3.35766657 4.45391302 1.38907859 2.30148079 4.63637723 3.45937412 2.94930292
## [15] 1.44009535 1.24663143 0.54124695 3.65451204 1.50108508 2.23773351 0.63007357
## [22] 2.62351713 2.37921356 0.07420163 2.12444757 4.67965217 4.44459193 1.39030676
## [29] 4.99919658 1.83741560 1.42966575 1.64082222 0.80555428 2.14070414 2.63217911
## [36] 1.20162470 0.47279641 4.33864937 4.72580666
##
## $chain1$log_p10
## [1] -2.796633
##
## $chain1$alpha
## [1] 0.1964461
##
## $chain1$p_dna
## numeric(0)
##
## $chain1$p11_dna
## numeric(0)
##
##
## $chain2
## $chain2$mu_trad
## [1] 0.87276147 2.03188587 0.66084314 0.13438534 4.06042785 0.22152301 4.68603817
## [8] 2.05313538 1.46450040 2.53454562 0.72649336 0.74058932 1.32905034 2.23694431
## [15] 1.39082139 4.30714801 0.26816394 3.70079946 0.84553286 4.23649201 3.21526805
## [22] 0.68326589 3.60168303 4.11148904 3.63644667 3.59252940 2.65703635 0.52038280
## [29] 0.03507528 4.38929181 2.86513920 0.25343151 1.30054310 4.57305874 4.18419211
## [36] 2.41816818 2.53412632 2.24256150 4.17622670
##
## $chain2$mu
## [1] 0.87276147 2.03188587 0.66084314 0.13438534 4.06042785 0.22152301 4.68603817
## [8] 2.05313538 1.46450040 2.53454562 0.72649336 0.74058932 1.32905034 2.23694431
## [15] 1.39082139 4.30714801 0.26816394 3.70079946 0.84553286 4.23649201 3.21526805
## [22] 0.68326589 3.60168303 4.11148904 3.63644667 3.59252940 2.65703635 0.52038280
## [29] 0.03507528 4.38929181 2.86513920 0.25343151 1.30054310 4.57305874 4.18419211
## [36] 2.41816818 2.53412632 2.24256150 4.17622670
##
## $chain2$log_p10
## [1] -5.186996
##
## $chain2$alpha
## [1] 0.1913759
##
## $chain2$p_dna
## numeric(0)
##
## $chain2$p11_dna
## numeric(0)
##
##
## $chain3
## $chain3$mu_trad
## [1] 4.08563641 3.00458869 4.86041058 3.93653214 0.64356493 0.82051093 4.54138165
## [8] 1.66956767 1.54175008 2.99839939 3.42348614 3.15147746 4.89434483 0.89496948
## [15] 3.85835434 4.99061882 2.82049357 4.92928634 2.04521894 4.72840884 0.92663132
## [22] 1.65902106 2.72229486 4.25293549 1.08461118 2.93773124 3.92963524 2.31247705
## [29] 0.75183797 3.59886763 4.85018954 0.92301433 0.51115093 2.55162753 0.51181698
## [36] 4.04090833 0.55995434 0.48406668 0.01155437
##
## $chain3$mu
## [1] 4.08563641 3.00458869 4.86041058 3.93653214 0.64356493 0.82051093 4.54138165
## [8] 1.66956767 1.54175008 2.99839939 3.42348614 3.15147746 4.89434483 0.89496948
## [15] 3.85835434 4.99061882 2.82049357 4.92928634 2.04521894 4.72840884 0.92663132
## [22] 1.65902106 2.72229486 4.25293549 1.08461118 2.93773124 3.92963524 2.31247705
## [29] 0.75183797 3.59886763 4.85018954 0.92301433 0.51115093 2.55162753 0.51181698
## [36] 4.04090833 0.55995434 0.48406668 0.01155437
##
## $chain3$log_p10
## [1] -3.525035
##
## $chain3$alpha
## [1] 0.09050999
##
## $chain3$p_dna
## numeric(0)
##
## $chain3$p11_dna
## numeric(0)
##
##
## $chain4
## $chain4$mu_trad
## [1] 4.8169377 1.3040600 4.4521831 4.2318351 0.2327441 3.0796919 4.6073282 3.1599987
## [9] 1.7016498 3.7740258 2.8673395 0.1553615 1.9518511 3.3902703 0.0488221 3.5183041
## [17] 0.7290816 4.5908417 3.5544107 0.6905151 2.1896665 3.0289190 2.8857307 1.9865807
## [25] 3.1955446 3.2327213 4.3636447 0.1574381 3.8810575 0.5552321 4.3065135 2.4638507
## [33] 3.5589756 3.8352929 1.6335797 4.9370987 0.9568528 4.3223653 3.2234160
##
## $chain4$mu
## [1] 4.8169377 1.3040600 4.4521831 4.2318351 0.2327441 3.0796919 4.6073282 3.1599987
## [9] 1.7016498 3.7740258 2.8673395 0.1553615 1.9518511 3.3902703 0.0488221 3.5183041
## [17] 0.7290816 4.5908417 3.5544107 0.6905151 2.1896665 3.0289190 2.8857307 1.9865807
## [25] 3.1955446 3.2327213 4.3636447 0.1574381 3.8810575 0.5552321 4.3065135 2.4638507
## [33] 3.5589756 3.8352929 1.6335797 4.9370987 0.9568528 4.3223653 3.2234160
##
## $chain4$log_p10
## [1] -2.949329
##
## $chain4$alpha
## [1] 0.1167025
##
## $chain4$p_dna
## numeric(0)
##
## $chain4$p11_dna
## numeric(0)3.6 Customize the MCMC
A few arguments can be used to customize the MCMC sampling. These arguments should be provided to joint_model() or traditional_model():
multicore: A logical value indicating whether to parallelize chains with multiple cores. If TRUE, the package usesparallel::detectCores()to determine the number of cores to use. Default is FALSE.n_chain: Number of MCMC chains. Default value is 4.n_warmup: A positive integer specifying the number of warm-up MCMC iterations. Default value is 500.n_iter: A positive integer specifying the number of iterations for each chain (including warmup). Default value is 3000.thin: A positive integer specifying the period for saving samples. Default value is 1.adapt_delta: Numeric value between 0 and 1 indicating target average acceptance probability used inrstan::sampling. Default value is 0.9.verbose: Logical value controlling the verbosity of output (i.e., warnings, messages, progress bar). Default is TRUE.